






Three architectural patterns for pay-per-use data lakes and data warehouses
Table of contents
To kick-off the serverless re:Invent series, we'll start with one on AWS data engineering. It is based on re:Invent session PEX-305-R and touches upon a large set of serverless services. The main goal is to illustrate how these services can work together to form a serverless ETL flow for streaming (or batch processing) applications.
NOTE: This is definitely not an architecture that you need to start out with as it will probably be over-engineered for small use-cases. However, parts of it you can apply to your own models.
The architecture of a feature-rich serverless streaming ETL flow
Below you can a complete overview of a feature-rich serverless ETL flow in AWS. Various components are highlighted below and some of the architectural patterns are discussed more in-depth.
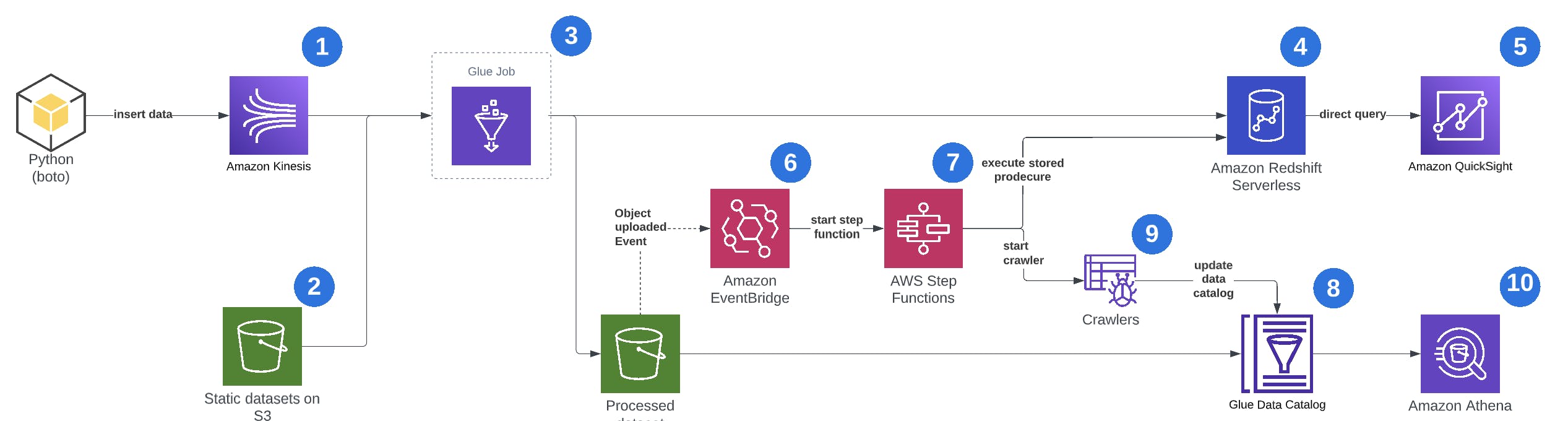
An overview of serverless data services used:
- Amazon Kinesis for streaming. Data can be inserted into the stream using any programming language.
- S3 for storage of static, raw or processed data.
- Glue jobs for ETL jobs and streaming ETL jobs, from multiple sources and to multiple destinations.
- Redshift serverless for the data warehouse.
- QuickSight for dashboarding and insights on data present in redshift.
- EventBridge for event-based orchestration.
- Step functions for workflow-based orchestration to kick off the crawlers.
- Glue crawlers to keep the data catalog up to date when new partitions are being added.
- Glue data catalog to be able to connect to datasets with other AWS services like Athena.
- Athena for ad-hoc SQL queries on large datasets on S3.
Pattern one - Glue jobs for data streaming
Glue jobs are basically spark scripts that can read from one or more data sources, transform and clean data, and then store the result in another data store. With glue data streaming, the glue job is continuously running and reading from a data stream like AWS Kinesis. It will read data in batches of N records and process then based on the job definition. An example of a visual job definition is given below:
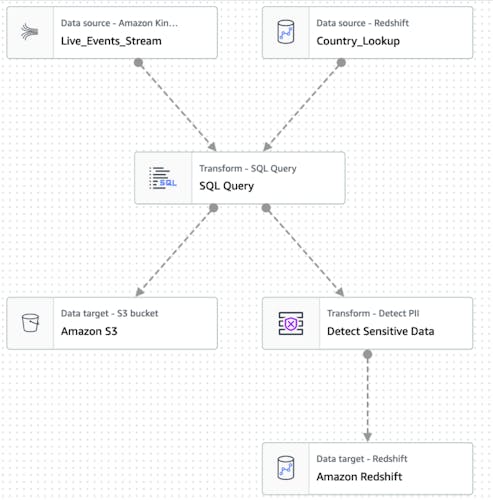
In the example above, a custom SQL query is used to query both a streaming data source and a static data source like S3 and combine that data and dump it in two locations. Firstly in S3 in for example a partitioned format based on a date-field. Secondly, it further processes the data and dumps it to Redshift.
A cool thing to note is the Detect sensitive data action. You can the glue job to configure to look for common sensitive data fields like email addresses, and choose to omit them or obscure them. In this example, the obscured data is stored in redshift to be safely made available for data analysts.
Pattern two - Redshift serverless and QuickSight for reporting
If you use QuickSight for generating scheduled reports or, maybe even cooler, ask questions in natural language using QuickSight Q, this is something for you.
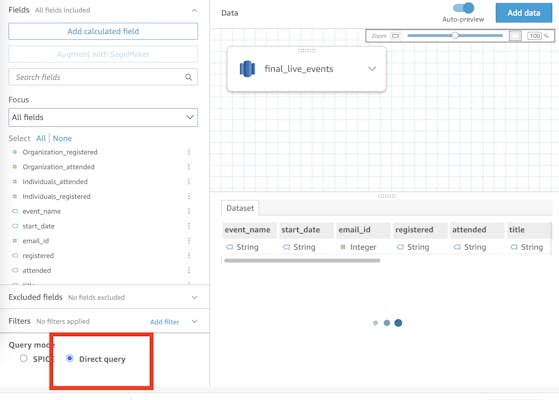
You can create a data source in QuickSight and connect it to a Redshift serverless cluster. Make sure to use 'Direct Query' mode (see image below) to make use of Redshifts native performance. If you don't do this, QuickSight will actually replicate the data and use its own storage to answer to queries.
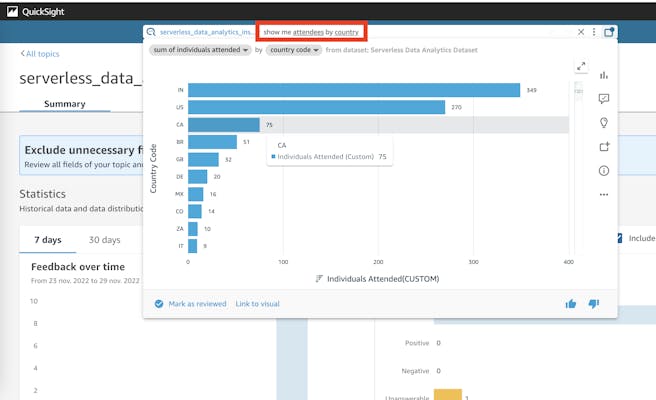
You can now for example use QuickSight Q to answer questions about your data. In the example below, you can ask to show me attendees by country and Q will automatically try to understand which fields need to be displayed and aggregated.
Pattern three - automated updates of glue data catalog for Athena
One cool pattern is to automatically update your data catalogs as new data is coming in. Data catalogs are used to optimize queries by providing the query engine where it can find certain partitions of data so it doesn't need to read all files in S3 before answering to the query.
You can do this using S3, AWS EventBridge and Glue crawlers. As a new object is created, automatically an event is emitted. EventBridge can be configured to automatically start a workflow with AWS StepFunctions when this happens. Step functions can do many things, like invoke a lambda that runs a query to update a materialized view in your database, but also to start a Glue crawler. An example step function is shown below.
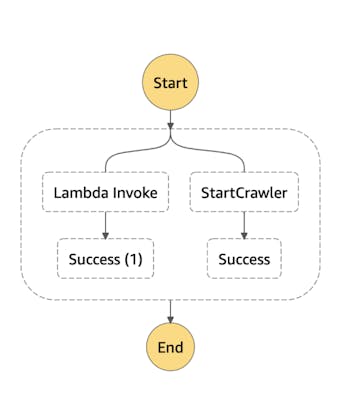
Glue crawlers crawl your S3 bucket for new partitions and data, and update the data catalog when it finds new partitions. This makes sure that your catalog is always up to date as new files are being added! This is great if you use AWS Athena to query these datasets, since it makes heavy use of the Glue Data catalog.
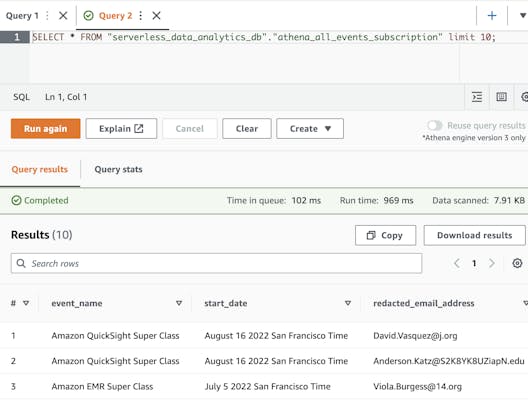
An example of such an Athena query is shown below. Note that the email addresses are not obscured here, as was intended.
More to come!
Hopefully you have an understanding of various architectural patterns in serverless ETL flows. In the next days, I will give some more updates in RDS aurora serverless V2, and AWS EMR serverless and how and when to use them. Stay tuned!
--
This blog also appeared on cloudengineer.hashnode.dev





